Improving Sequential Programs with Multithreaded Data Structure
Aaron Anderson & Justus Hibshman
15-418 Final Project Writeup
Summary:
As a handy utility, we created a “Sorted Collection” data structure utilizing parallelism. The data structure is actually composed of two data structures (tree-based and array-based) each maintained behind the scenes by their own thread. Lookups are serviced by the array if possible, but by the tree if necessary. We analyzed our code’s performance running on multiple machines and a wide variety of trace files we generated, using a single-threaded tree-based structure as a general reference point.
Background:
The sorted collection interface supports inserts (by value), lookups (by relative position; e.g. “Give me the 10th smallest element”), and deletes (by relative position). Our sorted collection is comprised of both a tree and an array that contain the same data in sorted order. We also wrote trace file generation code and a testing harness, wherein we check the time spent on each data structure operation as well as how many requests are serviced by each particular sub data structure.
Sample output:
Serviced from tree: 88465
Serviced from array: 11812
Times it wasn't ready: 2538
SortedCollection timing took 1.86111 seconds to complete
=== Time spent in data structure operations: 0.318005s
=== Average insert time: 0.000153901ms
=== Average lookup time: 0.000956742ms
=== Average delete time: 0.000186919ms
The opportunity for parallelism comes from the fact that the data structures don’t need to be “up-to-date” until a lookup is requested. This allows updates to the structures to be handled asynchronously. When a lookup is performed, the main thread needs some way of knowing when one of the structures can handle its request.
Differing data structures will have better capacity to handle different types of loads. By maintaining several data structures asynchronously, we are able to handle many different types of loads well. Particularly, we perform especially well when the load changes throughout the runtime of the application.
Approach:
We used C++ templates to create our sorted collection. Pthreads, along with the standard library’s mutexes and condition variables were our tools for parallelism. We ran tests both on our own machines and on some Gates machines.
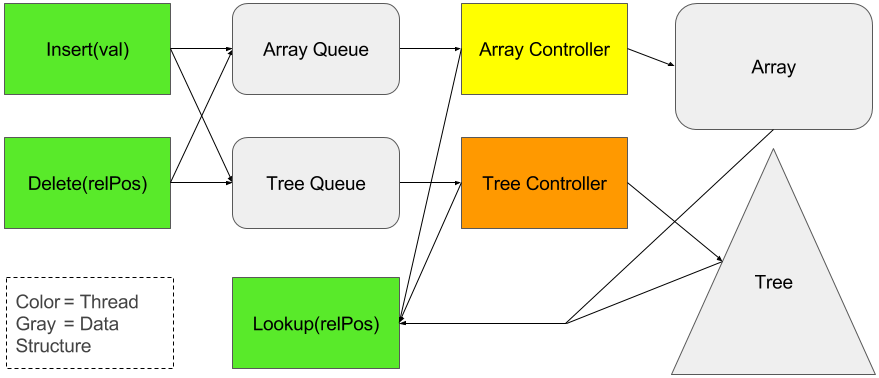
Diagram of Our Implementation’s Data Flow:
Gray entities are shared data structures. Other colors represent individual threads. The thread making use of the sorted collection (green) puts the modifications it wants to occur in two lock-free queues. The controllers then pull from the queues and perform the operations on the data structure. When the green thread wishes to perform a lookup, it gets data from the controllers concerning what’s up-to-date and accesses data as soon as a structure is ready. If it has a choice, it chooses the array for lookups.
The code for the lock-free queues is taken largely from the lecture slides with one important modification: The queue’s insert function reuses nodes in the reclaim chain instead of mallocing new queue nodes and freeing the reclaim nodes.
We tried to keep communication to a minimum as we knew this could be a major bottleneck in our application. The code is entirely lock-free with the exception of an occasional use of a lock in our latest version of the array controller. Synchronous communication only occurs on a lookup, as the main thread might need to wait for one of the substructures to service the lookup. In the case of inserts and deletes, the communication is handled by work queues which allow asynchronous operations with respect to the main thread.
The main thread keeps a counter of how many updates it entered. When it performs a lookup, it checks to see if the array or the tree controller has performed the same number of updates. (The fanciest version of the array has a slightly more involved check for the lookup. More on this later.)
The tree structure used is a standard single-threaded red-black tree written by Aaron last year as an independent project. However, we needed to augment it with size information in order to perform lookups by position. The array was the main focus of optimization, because Justus got out of hand and was very interested in the array (partly). We also optimized it in order to help it perform well alongside a tree—both to work well in tandem and to better keep up in more update-heavy situations.
Evolution of the Array:
As aforementioned, we performed a long series of upgrades and optimizations, in order to allow the array to perform faster and make better use of the fact that it runs asynchronously alongside a tree.
Optimization 1:
First, we moved the data from the beginning of our allocated block to the middle of it. That way, when we insert or delete, we can shift the data from whichever side requires less shifting.
Optimization 2:
Next, we added an insertion buffer so we could execute insertions in batch, amortizing the cost. The insertion buffer empties periodically and also before a delete operation is performed.
Optimization 3:
In this third modification, we turned the insert buffer into an insert-and-delete buffer. That way changes don’t need to be flushed whenever a delete appears; the buffer can be much larger. This implementation required careful reasoning about indices, the time that updates occur at, and the fact that we flush the updates in non-chronological order. This batching works well in tandem with the tree, because if the array gets behind, it can let the tree handle requests and start using larger batch sizes to catch up.
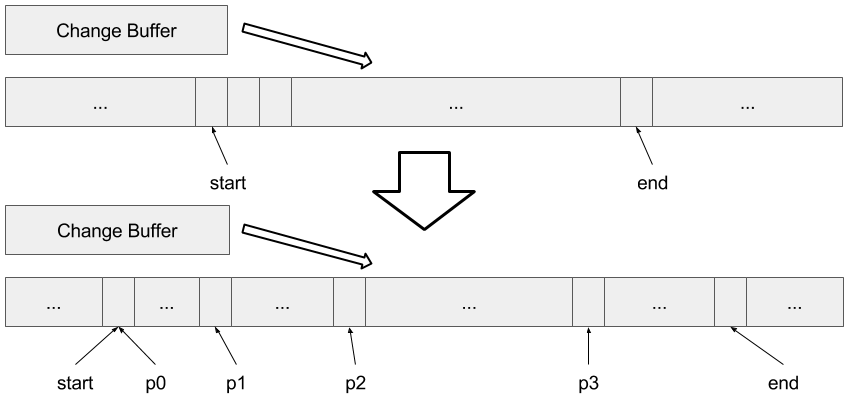
Optimization 4:
Next, we added some opportunities to access data even if the array isn’t fully up-to-date. We use several pointers to denote regions in the array that will be untouched by the buffered changes. Then, while changes are being flushed out, the pointers move, broadening the accessible ranges until the flush is complete and the whole array is accessible. It is in this version that we used a lock to protect calculations affected by an important jump in the start pointer’s position.
Finally, we made a hybrid version that switches between using a light version and using the change buffer (with its associated overhead) depending on how the array as a whole is handling the workload.
Testing:
The tests were performed using a randomly generated sequence (trace) of inserts, deletes, and lookups, according to various distributions, to model different workloads. We also added pauses between instructions to simulate other computation being done, and varied the length of these pauses as well. We tested on both GHC 43 (6-core Xeon W3670) and on a personal laptop (4-core i7-4700MQ). No other applications were running during testing on the laptop.
Our main trace distribution types were
The trace-runner’s pauses (simulating computation) were implemented by a spin-loop with a counter.
For benchmarks, we ran each trace on both a single-threaded red-black tree, and an asynchronous red-black tree (where inserts and deletes are queued and handled by a background thread). The code for the trees in the reference timings is the same as the code used in the sorted collection. We compared these reference timings with the timings obtained from our sorted collection for each trace distribution type across various trace lengths and pause times.
Results:
Results varied widely by trace file. In some cases, our code performed much worse than our tree running single-threaded. In other cases, having the asynchronous component was quite helpful, but the array simply added overhead. In still other cases, our code performed beautifully and far surpassed both the single-threaded and asynchronous trees.
Example of Performing Badly:
[Delay between ops = 100 int increments]
We perform poorly here because the space between data structure operations is so small that the minute benefits we get from asynchronization is overpowered by the overhead induced by our collection. Indeed, we see that as we increase the delay, our data structure gets better and better performance overall.
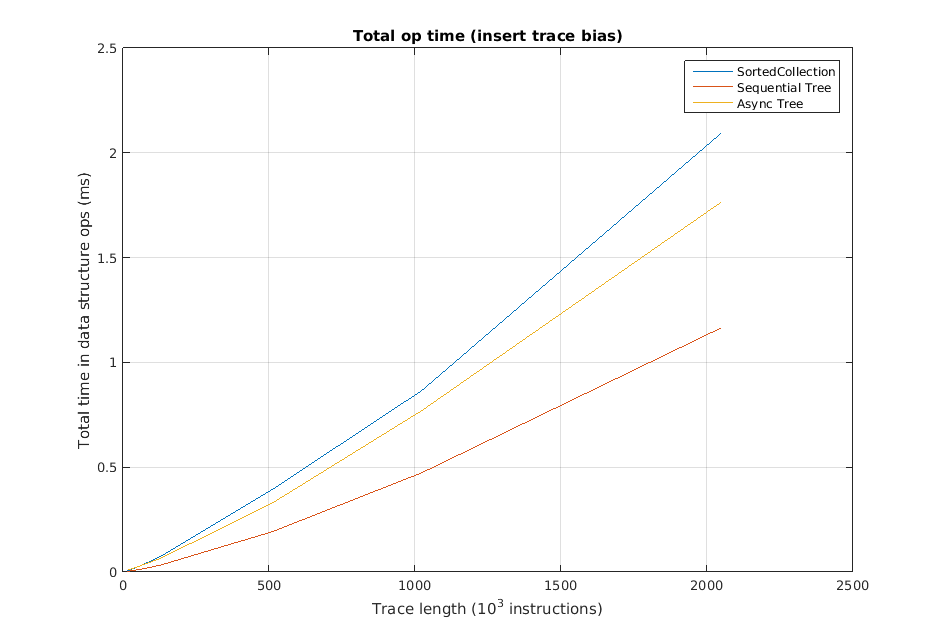
Example of Performing Well:
[Delay between ops = 1000 int increments]
We find the bottom-right of the above 4 graphs to be particularly interesting. In that graph, the sorted collection effectively matches the asynchronous tree in performance. This is an “equilibrium point,” where the overhead of having the array has been matched by the quick lookups it provides. Roughly 30% of the lookups in that graph are from the array. As the array sees more usage, the sorted collection will pass the async-tree in performance. If this progression continues for a long time, one would eventually be better off with just an asynchronous array, in the same way that some cases perform better with just an asynchronous tree. It is in the middle ground, or with less predictable traces, that our sorted collection is most useful.
Example of Performing Beautifully:
[Delay between ops = 5000 int increments]
As evidenced by the above lower-right graph, we can achieve more than 10x speedup over the sequential red-black tree and more than 5x over the asynchronous tree in particularly good cases.
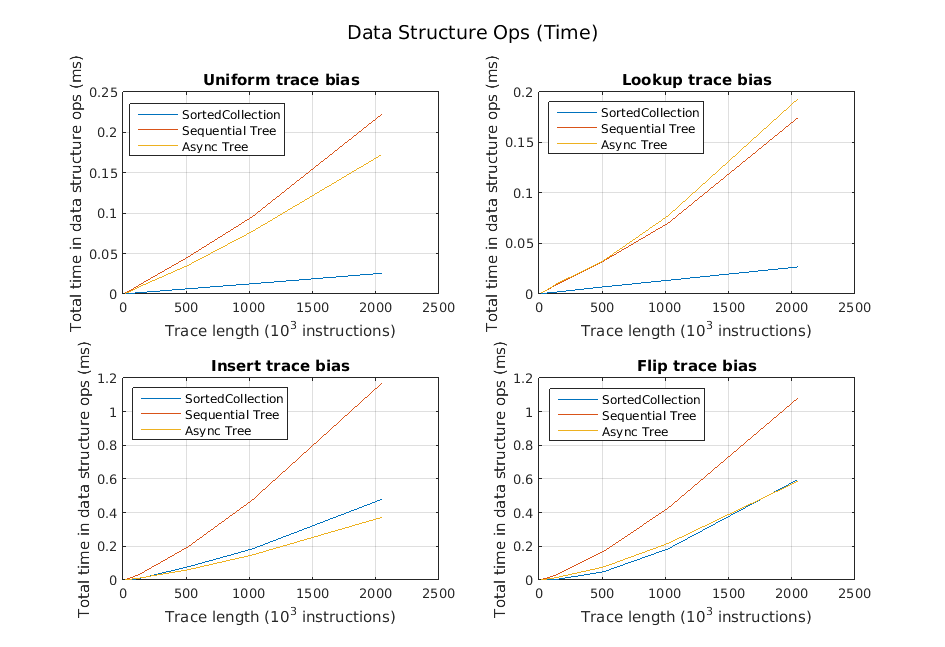
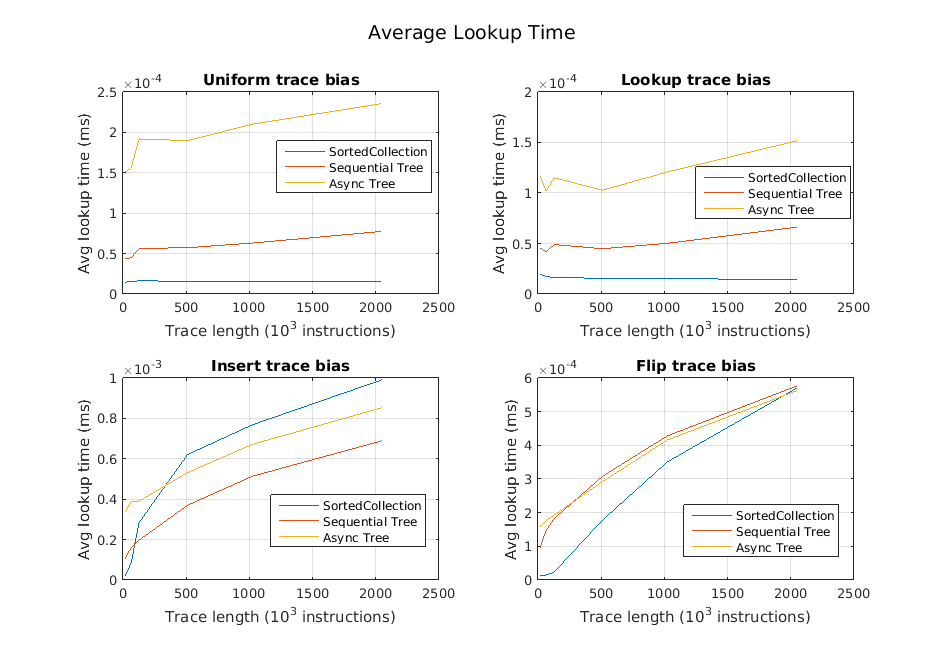
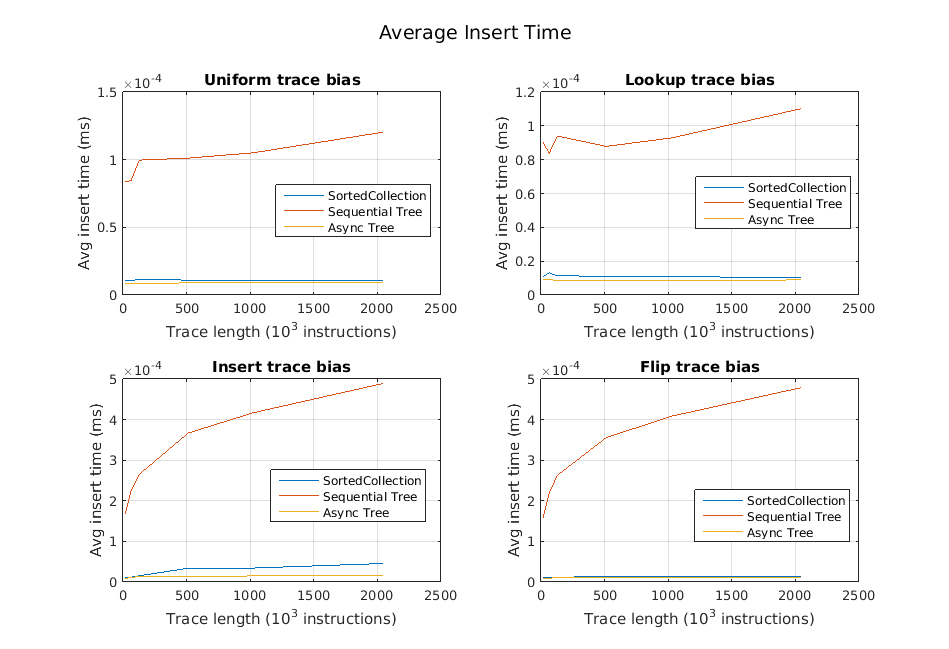
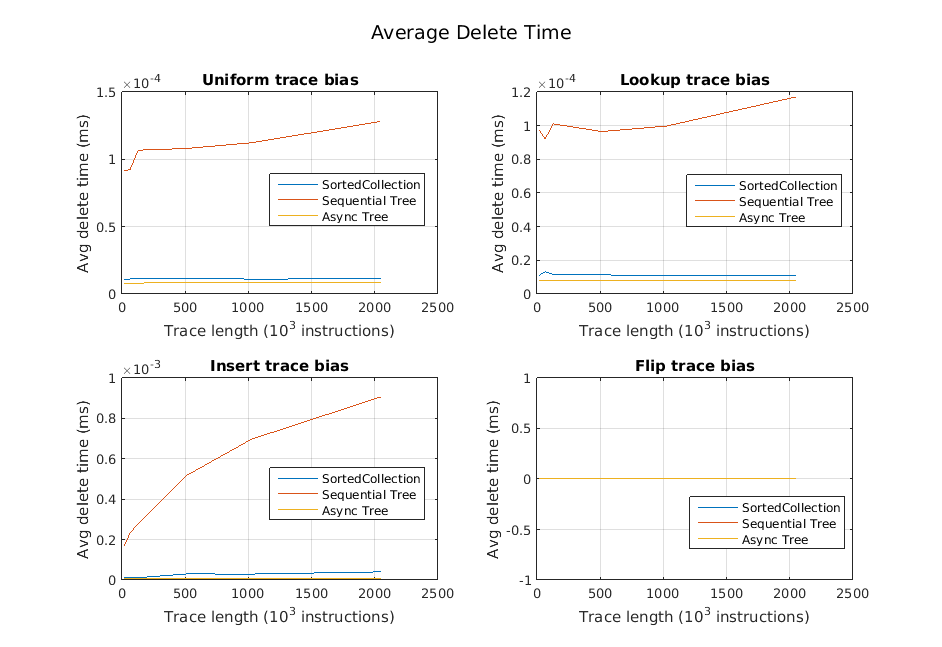
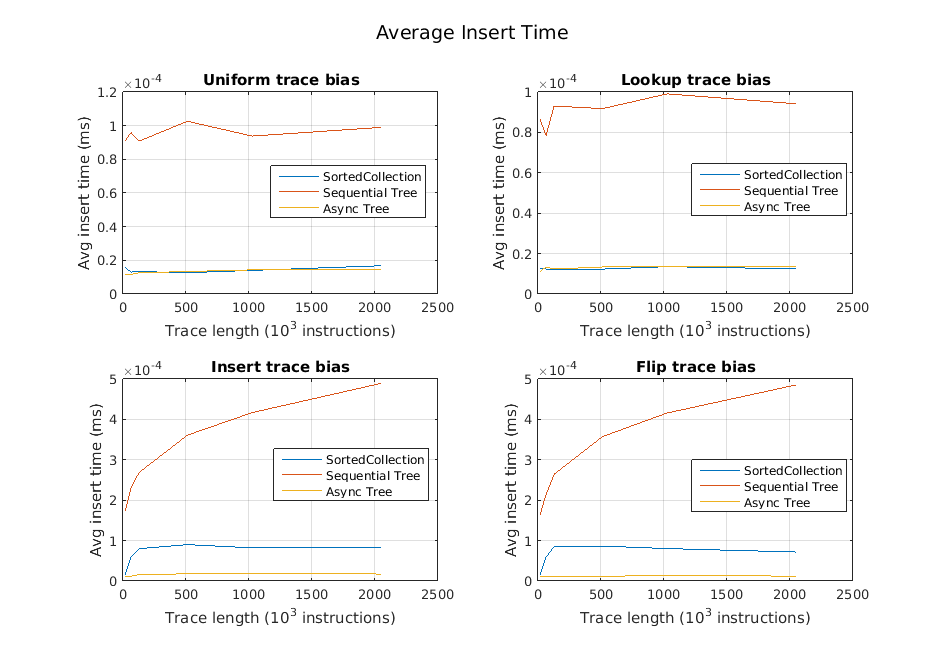
We also examined the average performance of each operation independently for the different types of traces. We found that the time spent for inserts and deletes was generally quite small, which we expected since they simply insert operations into the queue. Happily, we also found that in many cases, the lookups are much faster as well. These results are illustrated in the following three graphs.
[Delay between ops = 1000 int increments]
[Delay between ops = 1000 int increments]
[Delay between ops = 1000 int increments]
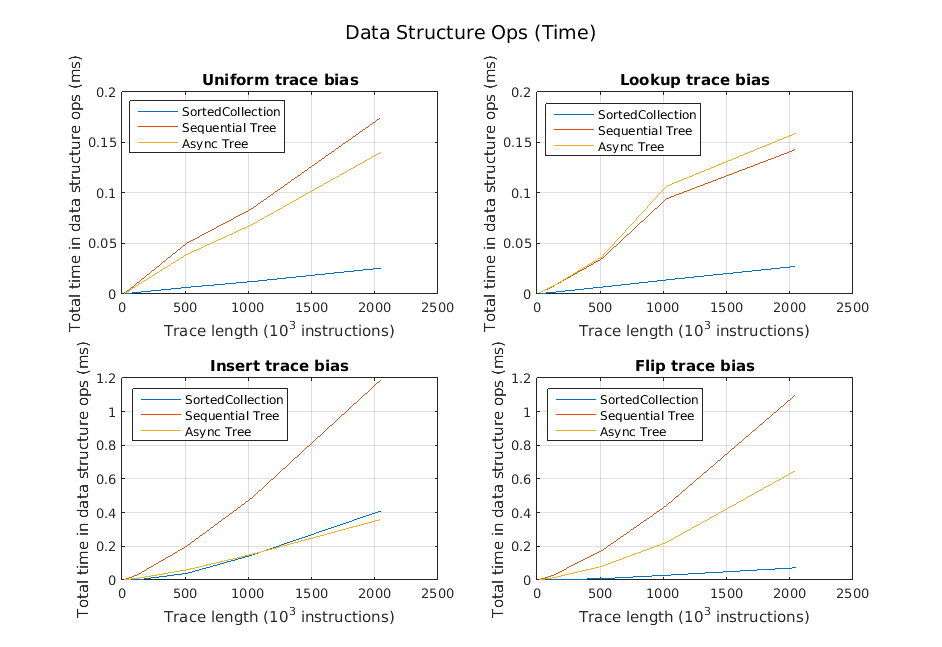
Generally, our inserts and deletes were very fast. However, in traces with short pauses and insert-heavy portions, the queue could start to take longer. Our belief is that this stems from the fact that as a queue gets seriously behind, the number of reclaim nodes available for reuse by the queue starts to dwindle, and calls to queue->insert() need to start allocating new queue nodes. These allocations are expensive. Note the two bottom graphs below:
[Delay between ops = 100 int increments]
To check if we were bandwidth bound, we ran an extra thread that used up memory bandwidth (calls to memcpy). Performance was minimally affected. This, of course, was for the machine we tested on. Given that our code is intended for a variety of systems, it doesn’t make complete sense to say “it’s bandwidth bound” or “it’s compute bound” because that will vary largely depending on the system which uses our code.
We note that there are several environments in which our code is most useful:
It is important to note that the machine having sufficient resources is quite important for good performance. Aaron’s laptop has an i5 processor with only two cores—and thus only two sets of execution resources (ALUs, etc). With three threads total in the program (the main thread plus each substructure controller), not everything was able to run simultaneously, leading to a degradation in performance. When moving to a machine with more cores, the performance improved dramatically.
List of Work by Each Student:
Equal work was performed by both project members.